이번주 뉴스레터에는 이런 내용을 담았어요!
- LLM에서 "수면"이라는 단어를 빌린 두 논문이 각각 어떤 문제를 풀려 했는지 소개했습니다.
- 인간의 수면 메커니즘을 차용하여 LLM의 예측 성능을 향상시키는 방법을 소개했습니다.
- 깊이 잠들수록 추론이 깊어진다는 실험 결과가 무엇을 시사하는지 정리했습니다.
LLM을 재우면 더 똑똑해진다?
안녕하세요, 에디터 영이입니다. :)
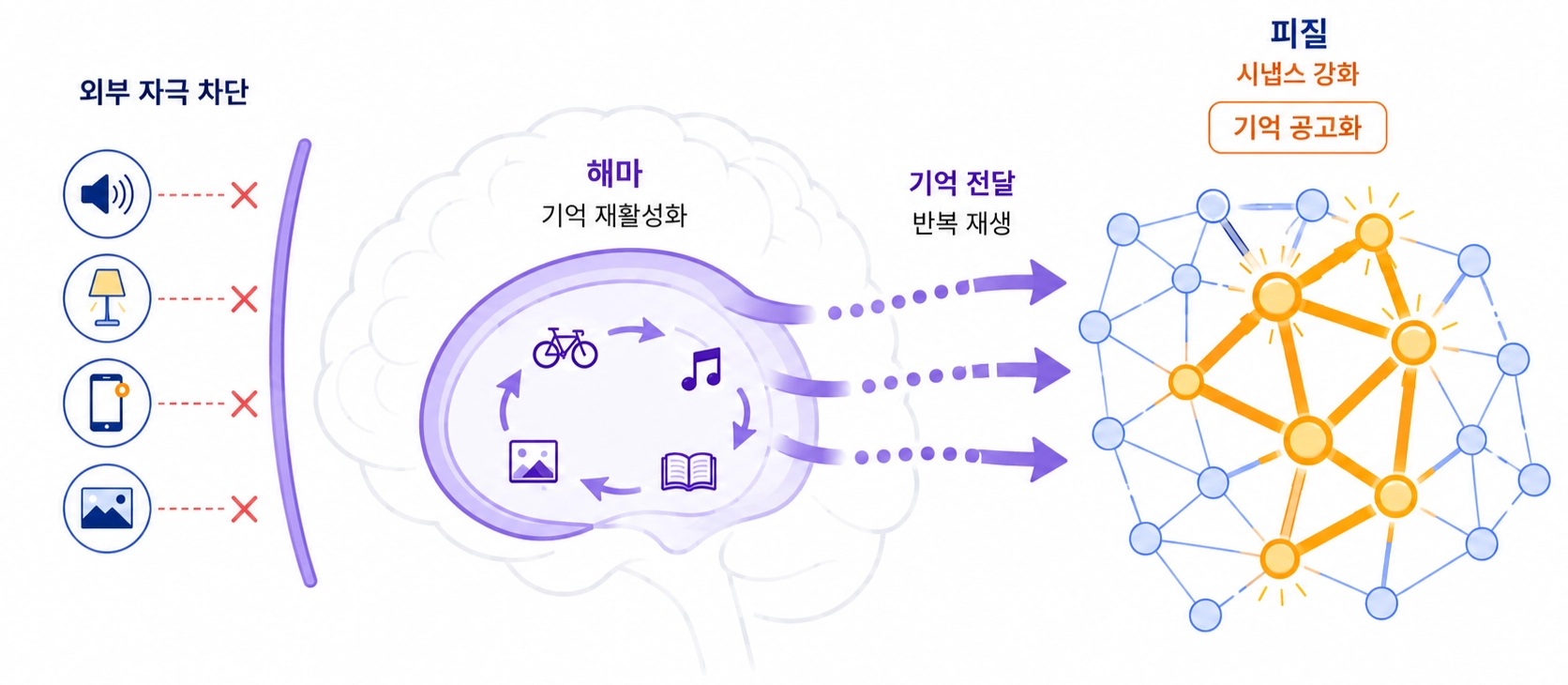
아무리 봐도 이해가 안 되던 개념이 다음 날 아침 눈을 뜨고 나면 어느새 머릿속에 정리되어 있던 경험, 코딩을 하다 몇 시간째 막혔던 버그가 다음 날 보면 어이없을 정도로 쉽게 풀리는 경험, 있으신가요? 이는 기분 탓이 아닙니다. 수면 중에 우리의 뇌는 낮 동안 해마에 임시 저장해뒀던 기억을 반복 재활성화(Hippocampal Replay)하면서 피질의 시냅스 가중치로 천천히 옮겨 굳힙니다. 자는 동안 아무것도 하지 않는 것처럼 보이지만, 사실 뇌는 그때 가장 바쁘게 정리 중입니다. 수면이 학습의 일부인 이유가 여기 있습니다.
그렇다면 LLM도 잠을 자면 더 잘 생각할까요? 이번 뉴스레터에서는 LLM에 수면 메커니즘을 접목시킨 연구를 두 가지 살펴보도록 하겠습니다.
자는 동안 생각하기
UC Berkeley와 Letta 팀의 Sleep-time Compute (Lin et al., 2025)는 많은 LLM 서비스는 근본적으로 쉬는 시간이 있습니다. 사용자가 다음 질문을 타이핑하는 동안 모델은 이전 대화의 맥락을 유지하고 있지만, 그 시간을 활용해 기억을 정리하거나 미래에 올 요청을 미리 계산하지 않습니다. 연구진은 이 쉬는 시간을 수면 시간(Sleep Time)으로 정의합니다. 구체적으로는 사용자의 쿼리가 아직 도착하지 않았지만 맥락은 이미 존재하는 시간입니다. 이 시간에 모델은 어떤 질문이 올지 예측하고, 그 답에 필요한 추론을 미리 해두는 방식으로 맥락을 처리합니다. 쿼리가 도착하는 순간이 곧 모델이 깨어나는 시점입니다.
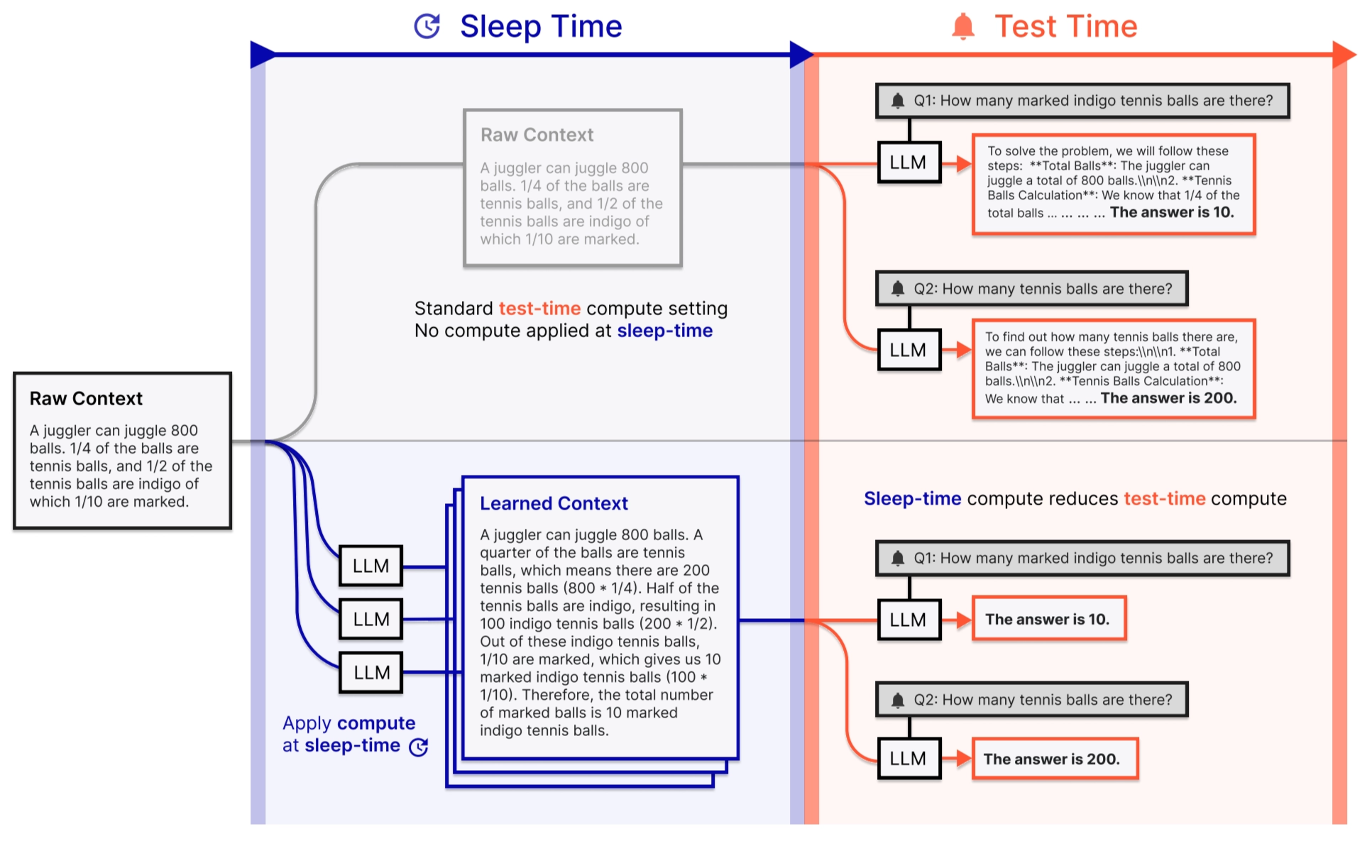
출처: Sleep-time Compute: Beyond Inference Scaling at Test-time (Lin et al., 2025)
코딩 어시스턴트를 예로 들어보면, 사용자가 다음 질문을 타이핑하는 동안 모델은 이미 코드베이스를 갖고 있습니다. 사용자의 쿼리를 기다리는 수면 시간에 코딩 어시스턴트는 코드베이스를 훑으면서 “곧 어떤 질문이 올 것 같은데, 그 답에 필요한 추론을 미리 해두자”고 생각하여 미리 추론을 준비해두는 것이죠.
실제로 이 방식은 수학 추론 벤치마크인 Stateful GSM-Symbolic과 Stateful AIME에서 Test Time 연산을 약 5배 절감하면서 동일한 정확도를 냈습니다. 또한 같은 맥락에 대해 여러 쿼리가 들어오는 상황에서는 미리 해둔 추론을 재사용할 수 있어서, 쿼리당 비용이 2.5배까지 줄어들었습니다.
효과는 분명하지만 작동 방식은 비교적 단순합니다. 모델에게 “이 문서를 미리 읽고 유용한 추론을 정리해둬”라고 프롬프트로 지시하는 방식이거든요. 모델 아키텍처 자체가 바뀌지는 않습니다. 수면이라는 단어를 빌렸지만, 그보다는 캐시 전략에 가깝습니다. 그렇다면 모델 자체가 더 잘 생각할 수 있도록 아키텍처 자체를 바꿔보는 건 어떨까요? CMU와 Maryland 팀의 <Do Language Models Need Sleep? Offline Recurrence for Improved Online Inference> (Lee et al., 2026)은 바로 이 질문에서 출발합니다.
기억은 충분한데, 왜 생각은 못 할까
Transformer 기반 LLM이 토큰을 읽어나갈 때, 이전에 읽은 내용은 KV Cache에 저장됩니다. 덕분에 모델은 앞서 본 모든 토큰을 직접 참조할 수 있습니다. 문제는 이 캐시가 시퀀스 길이에 비례해서 커진다는 점입니다. 토큰이 많아질수록 메모리는 선형으로 늘어나고, 연산량은 제곱으로 늘어납니다. 긴 문서를 다룰수록 비용이 가파르게 증가하는 구조입니다.
이 한계를 극복하기 위해 최근 많은 모델이 Attention 레이어 사이에 SSM(State Space Model) 레이어를 섞어 사용하고 있습니다. SSM은 KV Cache 대신 고정 크기의 Fast Weight에 과거 정보를 압축해 저장합니다. KV Cache가 이전 대화를 통째로 녹화한 영상이라면, Fast Weight는 핵심만 추려낸 요약본에 가깝습니다. 덕분에 맥락이 아무리 길어져도 메모리가 일정하게 유지되죠. Mamba 계열 모델이 이 방식이고, Qwen이나 Nemotron 같은 최신 모델도 이 하이브리드 구조를 채택하고 있습니다.
그런데 연구진은 여기서 메모리 용량이 문제가 아니라, 계산량이 문제라고 주장합니다. SSM이 정보를 담을 수는 있어도, 그 정보를 바탕으로 깊이 생각하는 건 별개의 문제라는 겁니다.
이를 보여주기 위해 연구진은 Rule 110이라는 과제를 선택했습니다. 이진 문자열이 정해진 규칙에 따라 한 단계씩 진화하는 단순한 시스템인데, 이론적으로 t단계 뒤의 상태를 예측하려면 반드시 t번의 순차 계산이 필요합니다. 계산을 뛰어넘는 지름길이 없고, 병렬화도 불가능합니다. 실험 설정은 이렇습니다. 4개의 독립적인 이진 문자열을 차례로 입력하고, 각 문자열이 t단계 진화했을 때의 첫 번째 비트를 맞혀야 합니다. 핵심 조건은 24 토큰마다 KV Cache를 완전히 비운다는 것입니다. 모델은 각 문자열을 보는 동안 그 내용을 Fast Weight에 완전히 새겨넣어야 하고, 예측 시점에는 KV Cache가 모두 사라진 상태입니다.
결과는 명확했습니다. 문자열 길이는 고정되어 있었으니 SSM이 담아야 할 정보량은 변하지 않았습니다. 그런데 t가 커질수록, 즉 더 많은 단계를 계산해야 할수록, SSM-Attention 하이브리드 모델의 성능이 급격히 무너졌습니다. 기억할 공간은 충분했지만, 생각할 연산이 부족했던 겁니다.
모델도 잠들어야 깊이 생각한다
이 문제를 어떻게 해결해야 할까요? 연구진은 사람의 수면 메커니즘에 주목했습니다. 수면 중 뇌에서는 두 가지 일이 동시에 일어납니다. 해마에 임시로 저장되어 있던 기억이 반복 재활성화되면서 피질의 시냅스 가중치로 천천히 옮겨 가 굳습니다. 그리고 이 과정이 진행되는 동안 외부 자극은 완전히 차단됩니다. 잠든 동안 새 정보를 받아들이지 못하도록 막는 것은, 외부 입력 없이 기존 기억을 반복하는 시간이 있어야 기억을 제대로 굳힐 수 있기 때문입니다.
논문은 이 구조를 그대로 가져옵니다. 시퀀스 처리 과정을 Consolidation Phase, 즉 맥락을 읽고 Fast Weight에 새기는 단계와, Prediction Phase, 즉 질문에 답하는 단계로 나누는 것입니다. 기존 모델도 이 두 단계가 암묵적으로 존재했지만, 둘 다 동일하게 단일 Forward Pass로 처리됐습니다. 연구진은 여기서 Consolidation Phase에만 반복 계산을 집중시키는 방법을 제안합니다. KV Cache가 꽉 차서 비워야 하는 순간, 즉 Eviction Boundary에 도달했을 때, 모델이 바로 캐시를 지우지 않고 현재 맥락 위에서 N번의 Forward Pass를 반복 수행하며, 이 과정을 수면(Sleep)이라고 정의했습니다. 수면 중에는 외부 입력 토큰을 받지 않습니다. 각 Pass마다 SSM의 Fast Weight가 조금씩 정제되고, N번이 끝나면 그제야 KV Cache를 비웁니다. 이후 Prediction Phase에서는 추가 루프 없이 평소처럼 단일 Forward Pass만 수행합니다.
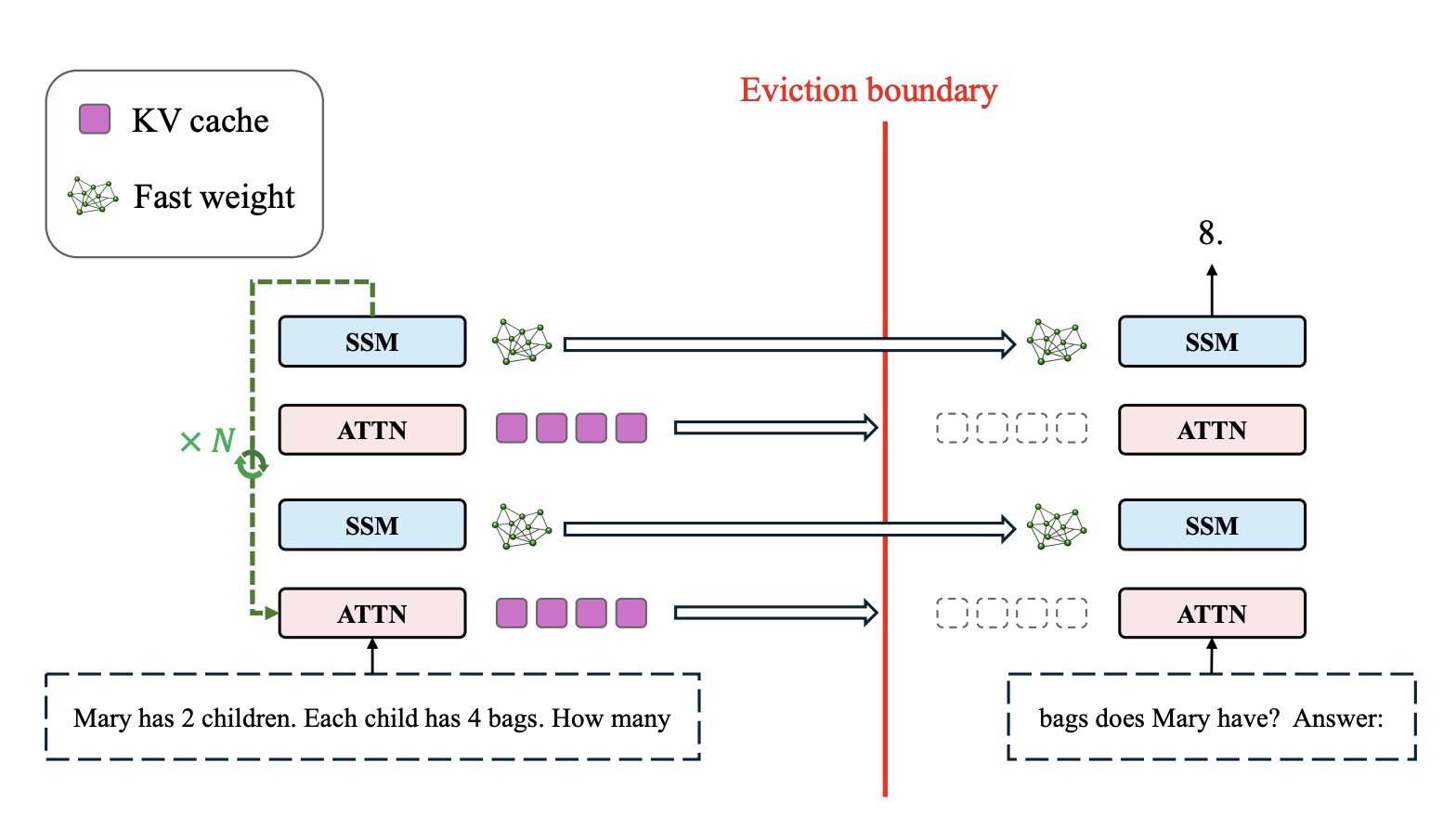
출처: Do Language Models Need Sleep? Offline Recurrence for Improved Online Inference (Lee et al., 2026)
왜 한 번이 아니라 여러 번 반복해야 할까요? Gradient Descent도 한 번의 업데이트로 수렴하지 않고 반복을 통해 점진적으로 개선되므로, Fast Weight를 한 번의 Pass로 완벽하게 만드는 것 역시 애초에 무리라는 것이 연구진의 주장입니다. 맥락을 유용한 가중치 표현으로 변환하는 과정은 반복할수록 더 정교하게 정제될 수 있습니다. 수면이 깊을수록 기억이 더 잘 굳는 것처럼요.
중요한 점은 이 추가 연산이 전부 수면 중에 소모된다는 겁니다. Prediction Phase는 항상 단일 Forward Pass로만 수행되므로, 사용자가 체감하는 추론 지연은 기존과 동일합니다.
깊게 잠들수록 추론도 깊어진다
수면은 정말 모델의 성능을 끌어올릴까요? 루프 수 N을 늘릴수록, 즉 수면을 깊게 할수록 더 많은 단계의 추론이 필요한 과제에서 정확도가 올라갔습니다. Rule 110에서는 t=32, 즉 32단계 진화를 예측해야 하는 가장 어려운 설정에서 루프가 없는 모델이 5B 토큰을 학습하고도 정확도 약 10%에 머물렀습니다. 루프 수가 늘수록 정확도가 꾸준히 상승하며, N=4의 경우 30%를 훌쩍 넘긴 정확도를 달성했습니다. 맥락 길이도, 예측 방식도 그대로인데 수면 깊이만 바꿨더니 더 좋은 성능을 낸 것입니다.
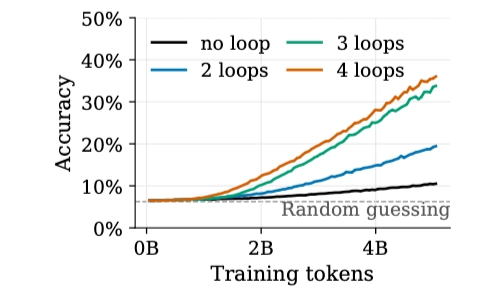
출처: Do Language Models Need Sleep? Offline Recurrence for Improved Online Inference (Lee et al., 2026)
더 복잡한 그래프 추론 과제(Depo)와 실제 수학 문장제 문제(GSM-Infinite)로 넘어가도 패턴은 동일했습니다. 쉬운 문제에서는 루프 수가 거의 영향을 미치지 않았고, 난이도가 올라갈수록 격차가 벌어졌습니다. 수학 과제에서는 어려운 문제 기준으로 루프가 4개인 모델이 루프 없는 모델 대비 최대 47% 높은 정확도를 보였습니다. 이 결과는 깊은 추론이 필요한 문제일수록 수면이 결정적인 차이를 만든다는 것을 보여줍니다.
한 가지 더 주목할 점은 이 효과가 처음부터 새로 학습한 모델에서만 나타나지 않았다는 겁니다. 서로 구조가 다른 Jet-Nemotron 2B, Ouro 1.4B 같은 기존 사전 학습 모델에 Fine-tuning으로 수면을 적용했을 때도 동일한 패턴이 나타났습니다. 아키텍처를 처음부터 다시 설계하는 대신 이미 잘 학습된 모델에 수면 메커니즘을 얹는 것만으로도 효과가 있다는 뜻이므로, 실제 서비스에 적용하는 데 비용이 적게 든다는 장점이 있습니다. 아키텍처 방식이 달라도 수면의 효과는 일관되게 나타났다는 점 또한 긍정적입니다.
반면 한계도 명확합니다. 가장 큰 문제는 학습 방식이 근본적으로 바뀐다는 점입니다. 기존 Transformer 학습은 시퀀스 안의 모든 토큰 위치를 병렬로 처리할 수 있습니다. 그런데 수면이 도입되면 캐시 윈도우 j를 처리하고 N번 수면을 마쳐야 윈도우 j+1을 처리할 수 있습니다. 시퀀스 축을 따라 순차적인 의존성이 생기는 겁니다.
루프 수만큼 훈련 비용이 선형으로 늘어나는 것도 문제입니다. 루프가 4개인 모델은 루프 없는 모델 대비 훈련에 약 4배의 시간이 걸립니다. 또한 현재 실험은 수십억 파라미터 이하 규모에서만 검증됐습니다. 수백억 파라미터 규모로 확장했을 때 같은 패턴이 나타날지, 수학 추론이 아닌 일반적인 언어 이해나 창작 과제에서도 효과가 있는지는 아직 열린 질문입니다. 수면이 깊을수록 좋다면, 최적의 수면 깊이는 어떻게 결정해야 하는지도 앞으로 풀어야 할 문제입니다.
인간의 인지 과정에서 영감을 받아 AI를 설계하는 시도는 새로운 일이 아닙니다. 뉴런에서 시작한 신경망도, 진화에서 아이디어를 빌린 유전 알고리즘도 그 계보에 있습니다. 하지만 최근 들어 모방의 단위가 바뀌고 있습니다. 구조가 아니라 행동을, 형태가 아니라 과정을 닮으려는 시도가 등장하고 있기 때문이죠.
이미 현실 서비스에서도 등장하고 있습니다. OpenAI는 지난 6월 4일 ChatGPT의 새로운 메모리 시스템인 Dreaming을 발표했습니다. 뇌가 수면 중 꿈을 꾸며 기억을 정리하는 것에서 영감을 받았는데요. 기존에는 사용자가 직접 “이거 기억해줘”라고 말해야 저장됐지만, Dreaming은 대화가 없는 동안 백그라운드에서 과거 대화들을 자동으로 참조하고 기억을 정리합니다. 심지어 시간의 흐름도 반영해서, “7월에 싱가포르 여행 간다”는 기억이 여행이 끝나면 자동으로 업데이트된다고 합니다.
자고, 쉬고, 꿈꾸고, 반복하는 것. 어쩌면 생명과학이 AI 연구의 가장 풍부한 아이디어 원천이 되는 시대가 오고 있는지도 모릅니다. 우리가 당연하게 여기는 인간의 습관들이 다음 모델 설계의 힌트가 되는 것처럼요.