#145 위클리 딥 다이브 | 2026년 5월 27일
이번주 뉴스레터에는 이런 내용을 담았어요!
- 하나의 GPU가 추론의 모든 단계를 떠맡을 때 생기는 비효율을 정리했습니다.
- 추론을 '쪼개서' 각기 다른 하드웨어에 맡기는 Disaggregation의 흐름을 살펴봅니다.
- 칩을 넘어 모델까지 쪼개지는 흐름과, 분리가 가진 한계도 함께 짚었습니다.
GPU만으로는 부족하다: CPU의 귀환과 분해되는 AI 인프라
안녕하세요, 에디터 쏘입니다 :)
오늘은 요즘의 AI 인프라 시장이 어떻게 바뀌고 있는지, 그리고 왜 CPU가 다시 주목받고 있는지 이야기해보려고 합니다. 최근 ‘AI가 죽여놨던 Intel’이라는 평가를 받았던 Intel이 AI 때문에 다시 주목을 받고 있습니다. 바로 CPU 때문인데요. NVIDIA도 CPU 사업으로 진출하고 있습니다. NVIDIA의 Vera CPU는 원래 Rubin GPU와 함께 Vera Rubin 플랫폼을 구성하는 핵심 부품으로 공개됐는데, 이 Vera CPU를 떼어내 단독 제품으로 판매하기 시작했습니다. AMD의 CEO 리사 수(Lisa Su)도 AI 추론과 에이전트 수요 탓에 CPU 시장이 1년 전 누구도 예상하지 못한 속도로 공급 부족에 들어섰다고 진단했습니다.
왜 CPU가 AI 시대에 다시 중요해진 걸까요? 사실 이건 CPU만의 이야기가 아닙니다. AI 추론이라는 작업이 GPU 한 칩으로 다 처리하기엔 너무 복잡해지면서, 그 일을 잘게 '쪼개서' 각기 다른 칩에 나눠 맡기는 흐름이 생겼고, CPU의 부상은 그 흐름이 만든 여러 결과 중 하나입니다. 이 '쪼개기', 즉 Disaggregation이 오늘 이야기의 핵심입니다. CPU가 왜 뜨는지를 따라가다 보면, 자연스럽게 AI 인프라 전체가 어떻게 재편되고 있는지가 보일 겁니다.
GPU 한 장이 모든 걸 하면 생기는 일
본격적인 이야기에 앞서, 추론이 어떤 구조로 이뤄지는지 짚어야 합니다. 이 부분은 #127 Google, NVIDIA, DeepSeek의 최신 동향: HBM을 넘어서에서 자세히 다뤘으니, 여기서는 간단히 복기하겠습니다.
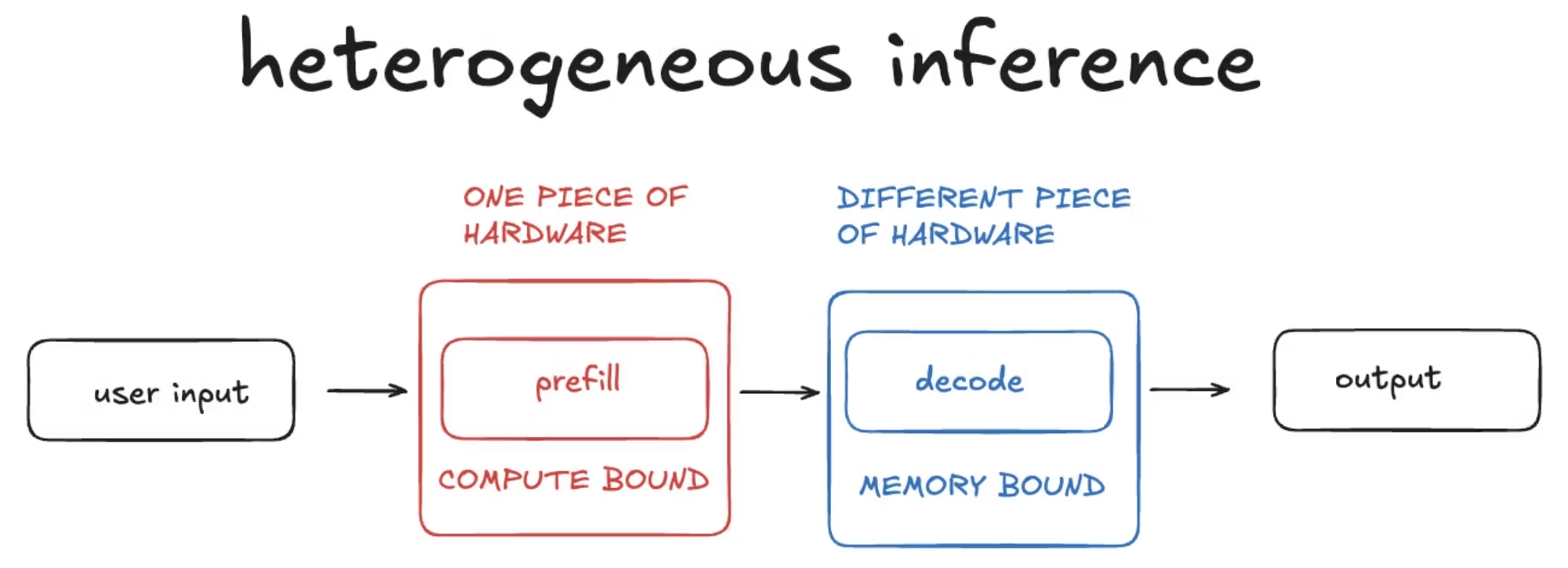
LLM 추론은 성격이 전혀 다른 두 단계로 나뉩니다. Prefill은 사용자의 입력 전체를 한 번에 읽고 처리하는 단계입니다. 모든 토큰을 동시에 처리하는 대규모 행렬곱이라, 연산량이 많고 GPU의 수천 개 코어를 빈틈없이 채울 수 있습니다. 연산이 병목인 Compute-bound 작업이죠.
Decode는 답변 토큰을 하나씩 순차적으로 생성하는 단계입니다. 앞 토큰이 나와야 다음 토큰을 예측할 수 있는 자기회귀 방식이고, 매 토큰마다 과거 토큰의 정보를 담은 KV 캐시를 메모리에서 읽어와야 합니다. 연산량 자체는 적은데 메모리에서 데이터를 끌어오는 속도가 전체 성능을 좌우하는, 메모리가 병목인 Memory-bound 작업입니다.
여기서 문제가 시작됩니다. 전통적인 추론 시스템은 이 두 단계를 같은 GPU 위에서 번갈아 실행했습니다. 그런데 한쪽은 연산이 부족하고 한쪽은 메모리 대역폭이 부족한, 요구사항이 정반대인 두 작업을 한 칩에 욱여넣으면 서로를 방해합니다. Prefill이 무거운 연산을 도는 동안 Decode 요청은 뒤에서 밀려 대기하고, 반대로 Decode가 메모리를 붙들고 있는 동안 GPU의 연산 코어 상당수는 놀게 됩니다.
직관적인 대응은 'GPU를 더 사는 것'입니다. 하지만 이렇게 하면 토큰당 비용은 오히려 오르고 지연시간은 좀처럼 줄지 않습니다. 두 작업을 한 칩에서 섞는 한, GPU를 아무리 늘려도 둘 중 어느 쪽도 제대로 서빙하지 못하는 자원에 돈을 쓰는 셈이기 때문입니다. 이 한계를 인식한 순간, 자연스럽게 다른 질문이 떠오릅니다. 두 작업을 굳이 같은 칩에서 돌릴 이유가 있을까?
CPU는 왜 갑자기 주목받게 됐나
Disaggregation 이야기를 본격적으로 하기 전에, 인텔과 AMD의 주가는 왜 동시에 뛰었고, 왜 하필 'CPU'가 다시 주인공이 됐을까요?
답은 AI 시대가 챗봇에서 에이전트로 옮겨가고 있다는 데 있습니다. 챗봇 시대에 CPU는 사용자의 입력을 정리해 GPU에 넘기고 결과를 후처리하는 보조 역할에 머물렀고, 무거운 연산은 전부 GPU 몫이었습니다.
그러나 에이전트 시대의 AI는 다릅니다. 한 번 답하고 끝나는 게 아니라, 스스로 계획을 세우고 도구를 호출하고 데이터베이스를 조회하고 그 결과를 받아 다음 행동을 정하는 과정을 반복합니다. 그런데 이 '도구를 호출하고 결과를 기다리는' 일은 GPU가 잘하는 일이 아닙니다. 웹 검색, 코드 실행, 데이터베이스 탐색, 작업 조율 같은 작업은 한 번에 묶어 처리할 병렬성이 거의 없고, 대신 순차적인 제어 흐름과 잦은 분기를 빠르게 처리하는 능력이 중요합니다. 바로 CPU가 수십 년간 최적화해 온 영역이죠.
문제는 에이전트 워크플로우에서 이 CPU 작업이 차지하는 비중이 생각보다 압도적이라는 데 있습니다. Georgia Tech와 Intel 연구진이 2025년 11월 발표한 논문은 다섯 종류의 대표적인 에이전트 워크로드를 측정했는데, CPU의 도구 처리가 차지하는 비중은 워크로드에 따라 갈렸지만 RAG나 분자 시뮬레이션처럼 도구가 무거운 작업에서는 전체 지연시간의 80~90%에 육박했습니다. RAG 워크로드에서는 문서 검색이, 코딩 에이전트에서는 bash와 Python 실행이 병목이었죠.
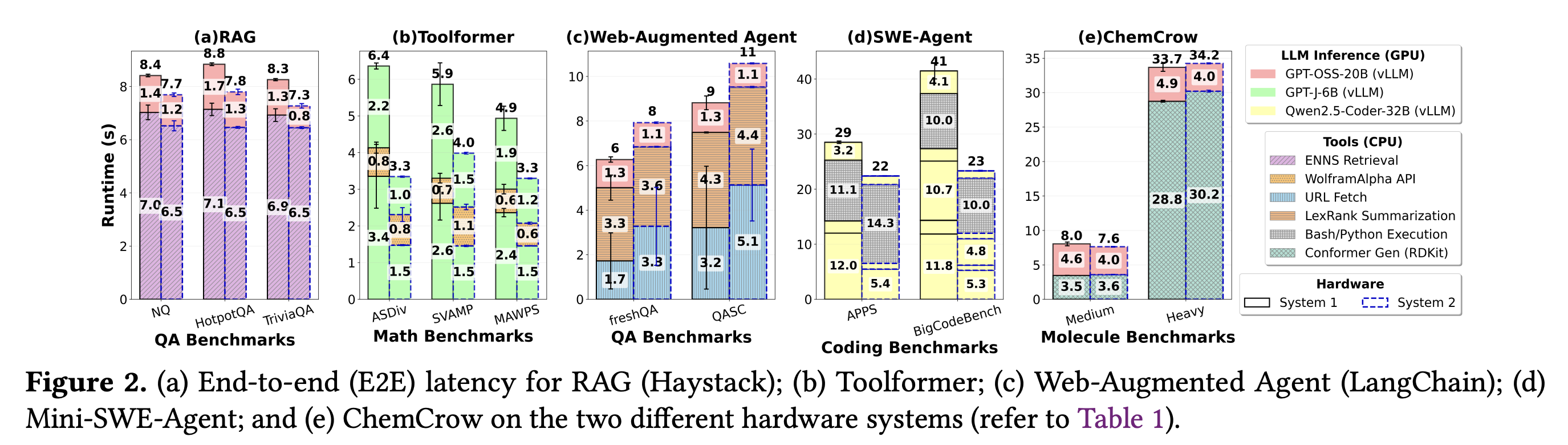
또한 GPU 성능이 좋아질수록 오히려 CPU 쪽이 더 큰 병목이 됩니다. 모델 연산이 빨라질수록, 그 사이사이의 도구 처리 시간이 상대적으로 더 도드라지기 때문입니다. 비싼 GPU를 살수록 그 GPU가 CPU의 처리를 기다리며 노는 시간이 더 눈에 띄게 되는 셈이죠.
인텔 CEO 립부 탄은 "추론으로 무게중심이 옮겨가는 상황에서 작업 조율과 제어, 여러 에이전트와 데이터 관리는 CPU가 더 효율적"이라고 말했습니다. 이어 데이터센터에서의 CPU 대 GPU 비율이 '과거 1:8이었지만 현재는 1:4까지 왔고, 앞으로는 1:1로 동등해지거나 CPU 비중이 더 커질 수 있다'고 말했습니다.
그렇다면 GPU가 못하는 일이 CPU 말고도 더 있을까요? 이 질문에 답하려면, 추론을 더 잘게 쪼개봐야 합니다.
첫 번째 분리: 추론 단계를 쪼갠다
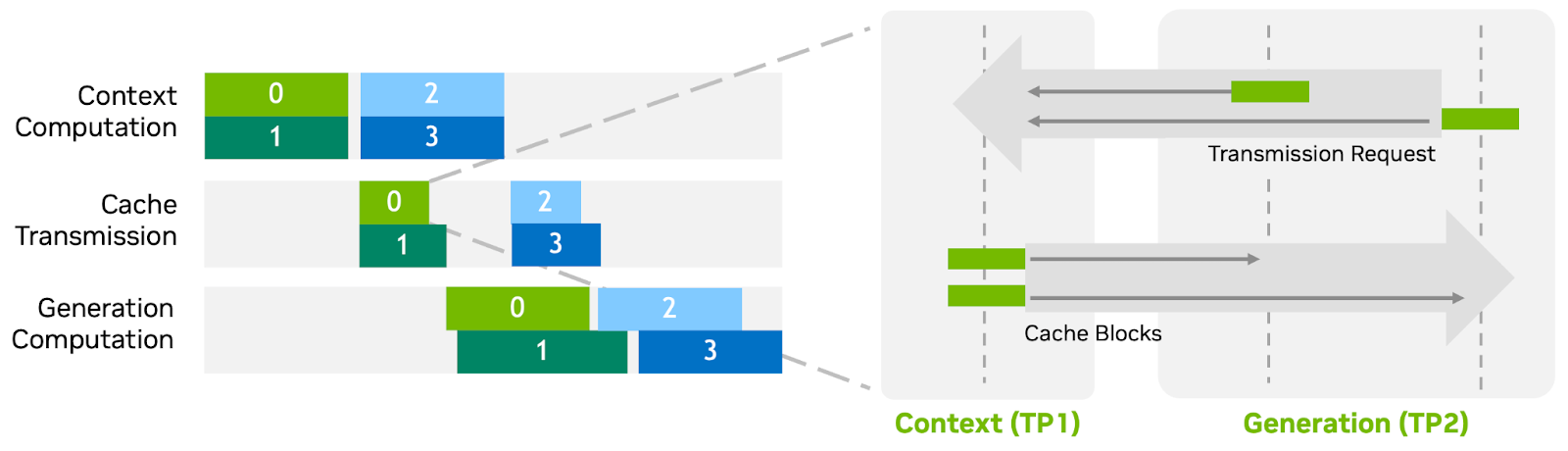
가장 먼저 나온 분리는 앞서 본 Prefill과 Decode를 갈라놓는 것입니다. ‘Prefill-Decode Disaggregation(PD 분리)’이라고 부릅니다. 아이디어 자체는 명쾌합니다. Prefill을 처리하는 GPU 풀과 Decode를 처리하는 GPU 풀을 물리적으로 분리하는 것입니다.
이렇게 나누면 각 풀이 자기 작업의 성격에만 맞춰 최적화할 수 있습니다. Prefill 풀은 연산 처리량을 극대화하는 방향으로, Decode 풀은 메모리 대역폭을 확보하는 방향으로 따로 튜닝됩니다. 두 단계가 서로의 자원을 두고 다투지 않으니 간섭이 사라지고, 무엇보다 두 풀을 독립적으로 확장할 수 있습니다. 입력이 긴 RAG 워크로드가 몰리면 Prefill 풀만 늘리고, 출력이 긴 추론 모델 요청이 많아지면 Decode 풀만 늘리는 식으로 수요에 맞춰 자원을 배분할 수 있는 것이죠.
이 구조는 2024년 Microsoft의 Splitwise와 DistServe 등을 비롯한 일련의 연구를 거치며 정립됐고, 2026년 현재는 대규모 LLM 서빙의 사실상 표준 아키텍처가 됐습니다.
물론 분리에는 대가가 따릅니다. Prefill 풀이 만든 KV 캐시를 Decode 풀로 네트워크를 통해 옮겨야 한다는 점입니다. 이 전송이 느리면 분리의 이점이 깎이기 때문에, 최근 연구는 여기를 정교하게 다듬는 데 집중하고 있습니다. 일례로 KV 캐시를 모든 연산이 다 끝날 때까지 기다렸다 한꺼번에 보내는 대신, 먼저 완성된 부분부터 즉시 전송하기 시작하는 식입니다. 앞부분의 캐시가 네트워크를 타고 이동하는 동안 GPU는 뒷부분의 연산을 계속 진행하죠. 연산과 통신을 시간적으로 겹쳐 전송 지연을 연산 시간 뒤에 숨기는 접근입니다.
분리가 표준이 되자, 연구는 한 걸음 더 들어갑니다. 2026년 3월 공개된 한 연구는 "모든 Prefill이 똑같지는 않다"는 점에 주목했습니다. 챗봇이나 에이전트처럼 대화가 여러 턴 이어지는 상황을 떠올려 보면 사용자가 새 메시지를 보낼 때마다, 모델은 그 새 입력만 처리하는 게 아니라 직전 턴에서 자신이 내놓은 답변까지 다시 읽어 KV 캐시에 반영해야 합니다. 매 턴 반복되는 이 작업을 'Append-Prefill'이라고 부르는데, 처음부터 긴 입력을 통째로 처리하는 일반적인 Prefill과는 성격이 사뭇 다릅니다. 분량이 짧고 가벼운 경우가 많거든요. 그래서 이 연구는 “가볍고 짧은 Append-Prefill까지 굳이 Prefill 풀로 보낼 게 아니라, 워크로드 특성에 따라 Decode 풀에서 바로 처리하게 하면 어떨까?”라는 아이디어에서 시작합니다. 같은 'Prefill'이라는 이름표가 붙어 있어도 그 안에서 무거운 작업과 가벼운 작업을 다시 갈라내자는 것이죠. PD Disaggregation이라는 큰 틀 안에서도 더 세밀한 분리가 계속 탐구되고 있음을 보여줍니다.
두 번째 분리: 레이어 내부를 쪼갠다
PD Disaggregation이 추론의 '단계'를 나눴다면, 그다음 분리는 한 레이어 '안'으로 파고듭니다.
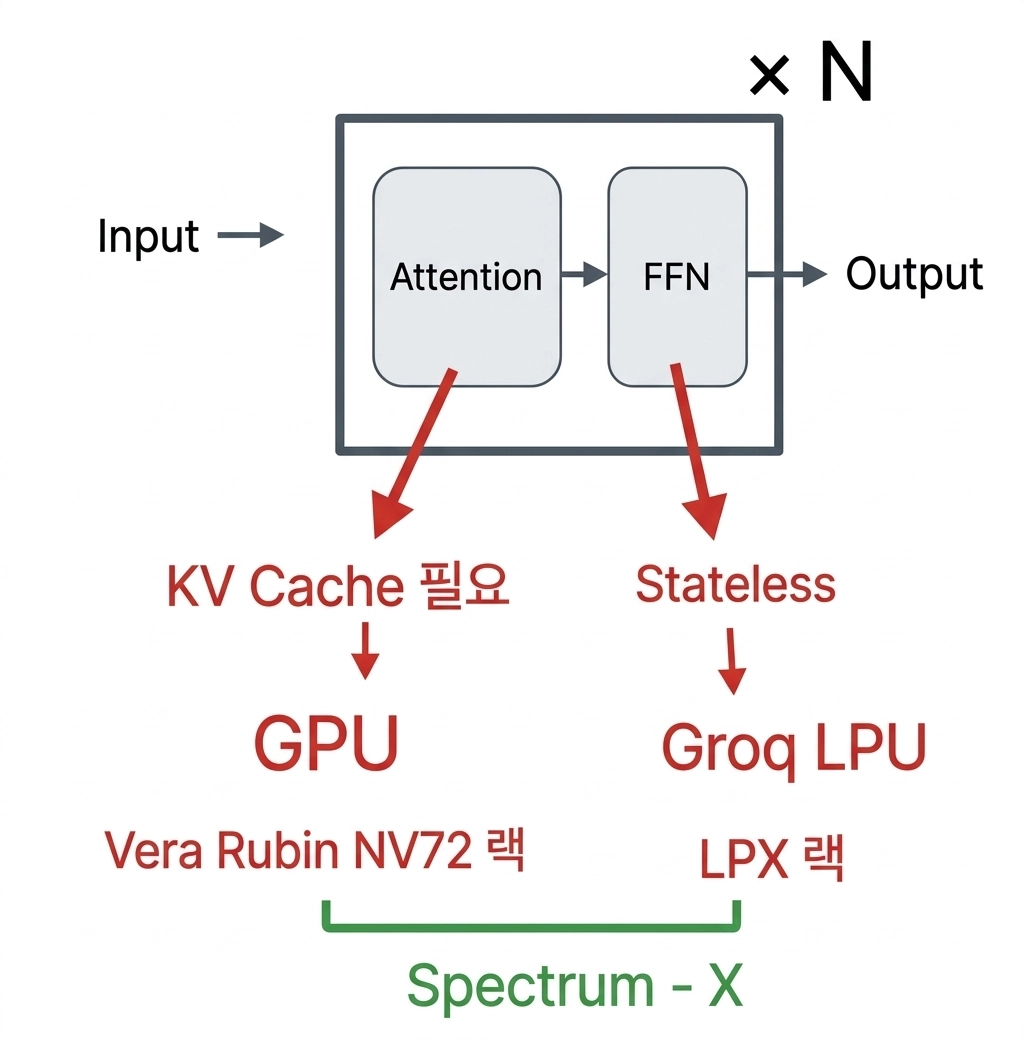
2025년 말, NVIDIA가 약 200억 달러를 들여 추론 칩 스타트업 Groq를 Acquihire 방식으로 인수하였습니다. GPU 시장을 사실상 독점한 회사가, 왜 굳이 다른 종류의 칩을 사들였을까요? 답은 NVIDIA가 Groq를 GPU의 경쟁자가 아니라 부품으로 봤다는 데 있습니다. 하나의 Transformer 레이어를 둘로 쪼개, 한쪽은 GPU에, 다른 한쪽은 Groq의 추론 특화 칩에 맡기려는 것이죠. 이렇게 한 Transformer 레이어를 구성하는 Attention과 FFN(Feed-Forward Network)을 분리하는 것이 바로 AFD(Attention-FFN Disaggregation) 입니다.
이 분리가 왜 필요한지는 MoE(Mixture of Experts) 모델의 확산과 직결됩니다. MoE는 기존 Transformer에서 모든 토큰이 통과하던 하나의 FFN을 여러 개의 Expert로 쪼개고, 각 토큰은 Router가 고른 일부 Expert만 통과하게 하는 구조입니다.
문제는 최신 MoE 모델일수록 점점 더 '희소(sparse)'해진다는 데 있습니다. Expert 수는 크게 늘리면서 토큰 하나가 활성화하는 Expert 수는 적게 유지하는 방향으로 발전하고 있죠. 2023년 Mixtral은 Expert 8개 중 2개를 썼지만, 2024년 DeepSeek-V3는 256개 중 8개를 씁니다. Expert 수는 32배 늘었는데 활성화 수는 4배 느는 데 그쳤습니다.
이게 왜 문제일까요? Decode 단계에서 동시에 처리 중인 요청이 400개라고 해봅시다. 이 토큰들이 Router를 거쳐 각 Expert로 흩어지는데, Expert 하나에 평균적으로 몇 개의 토큰이 도착하는지를 따져보면 됩니다. Mixtral이라면 Expert당 100개꼴이지만, DeepSeek-V3는 12.5개에 불과합니다. GPU는 많은 데이터를 한 번에 묶어 처리할 때 가장 효율적인데, Expert 하나가 받는 토큰이 12.5개면 사실상 행렬과 벡터를 곱하는 수준의 극소량 연산이 되어 GPU 코어 대부분이 놀게 됩니다.
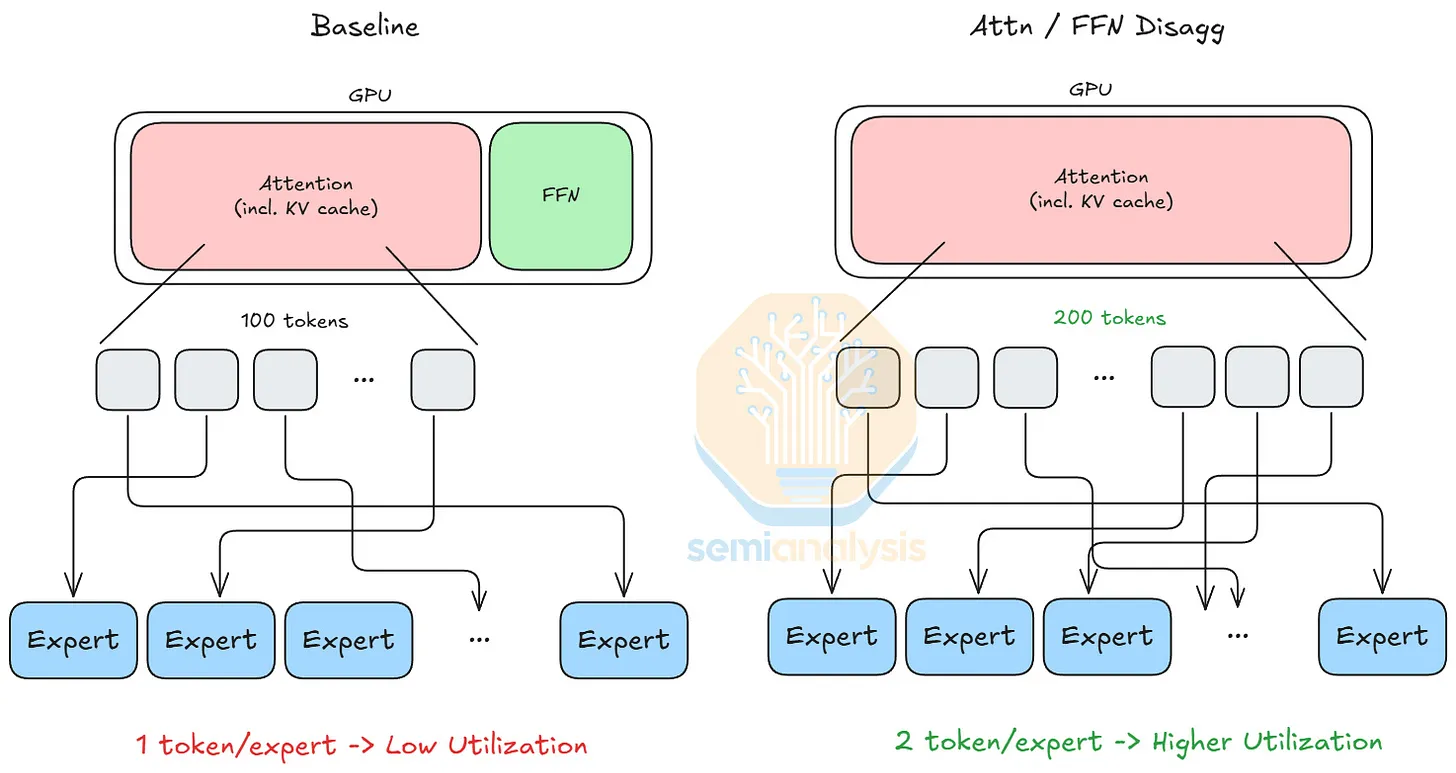
Attention과 FFN, 갈 길이 다른 두 연산
AFD의 발상은 이렇습니다. 한 레이어 안에서 Attention과 FFN은 요구하는 자원의 성격이 근본적으로 다릅니다. Attention은 시퀀스가 길어질수록 커지는 KV 캐시를 매 토큰 읽어야 하니 대용량 메모리가 필요한 작업이고, FFN은 과거 상태를 참조하지 않는(stateless) 순수한 행렬 곱이라 성격이 또 다릅니다. 그렇다면 이 둘을 같은 칩에 두지 말고, Attention 모듈과 FFN 모듈을 분리해 각자에게 맞는 하드웨어에 배치하자는 것입니다.
그리고 여기서 결정적인 관찰이 더해집니다. MoE의 희소성 때문에, FFN 연산이 연산 집약적(compute-intensive)에서 메모리 집약적(memory-intensive)으로 성격이 바뀐다는 것입니다. 원래 FFN은 연산량이 많은 작업이었지만, 토큰이 잘게 흩어지면서 거대한 Expert 가중치를 메모리에서 읽어오는 비용이 실제 연산보다 더 커진 것이죠. 이 통찰을 정면으로 다룬 것이 ByteDance가 2025년 발표한 MegaScale-Infer입니다. MegaScale-Infer는 메모리가 중요한 Attention에는 메모리 중심 GPU를, 연산이 중요한 FFN에는 연산 최적화 GPU를 배정하는 이종 하드웨어 배치를 실험했고, 동일 비용 대비 처리량을 의미 있게 끌어올렸습니다.
앞서 본 NVIDIA의 Groq 인수도 정확히 같은 논리 위에 있습니다. NVIDIA는 Groq를 GPU의 대체재가 아니라 보완재로 봤습니다. 메모리가 핵심인 Attention은 대용량 HBM을 가진 GPU가 맡고, 과거 상태를 참조하지 않는 대량 병렬 연산인 FFN은 Groq의 추론 특화 칩이 맡는 역할 분담이 가능했기 때문입니다. NVIDIA가 200억 달러를 들여 다른 종류의 칩까지 사들인 건, GPU 한 칩으로 레이어 전체를 감당하던 시대가 끝났다는 판단을 보여줍니다.
다만 AFD에는 까다로운 대가가 있습니다. Attention과 FFN을 다른 하드웨어에 두면, 토큰이 매 레이어마다 두 하드웨어 사이를 오가야 합니다. Router가 토큰을 흩뿌리는 패턴이 불규칙해서 어느 통신 경로에 부하가 몰릴지 예측하기 어렵고, 레이어가 수십 개면 이 왕복이 수십 번 반복됩니다. 하드웨어 연산이 아무리 빨라도 그 사이를 잇는 네트워크가 느리면 전체 속도가 통신에 묶여버리죠. MegaScale-Infer가 배치를 잘게 쪼개 통신과 연산을 시간적으로 겹치는 Ping-Pong 파이프라인을 함께 제안한 이유가 여기 있습니다.
실제로 2026년 2월에는 AFD를 현대 MoE 모델과 하드웨어에 적용할 때 부딪히는 난점들을 본격적으로 분석한 후속 연구도 나왔습니다. 분리가 깊어질수록 그것을 작동시키는 일도 그만큼 어려워진다는 신호입니다.
세 번째 분리: 모델 자체를 쪼갠다
지금까지의 분리가 '추론 단계'와 '레이어 내부'를 갈랐다면, 마지막 분리는 모델 단위로 올라갑니다.
가장 잘 알려진 사례는 Speculative Decoding입니다. 작고 빠른 Draft 모델과 크고 정확한 Target 모델, 두 개를 함께 쓰는 기법인데요. Draft 모델이 다음 토큰 후보 여러 개를 빠르게 제안하면, Target 모델이 그 후보들을 한 번의 Forward Pass에서 병렬로 검증합니다. 맞은 토큰은 확정하고 틀린 시점부터 다시 진행하죠. 최종 출력의 품질은 Target 모델로만 생성한 것과 동일하게 유지되면서, 거대한 모델을 매번 통째로 읽어 토큰 하나를 얻던 Decode의 비효율을 줄입니다.
이걸 분리의 관점에서 보면, '하나의 모델이 처리하던 토큰 생성'을 '제안'과 '검증'이라는 두 역할로 쪼갠 것입니다. 그리고 이 두 역할도 서로 다른 하드웨어 특성을 요구합니다. 토큰을 하나씩 빠르게 뽑는 Draft는 저지연 순차 연산에, 여러 토큰을 한 번에 처리하는 Target의 검증은 병렬 연산에 강한 하드웨어가 어울립니다.
분리가 한 번 더 올라가면, 모델 단위 쪼개기는 한 모델 안이 아니라 여러 개의 독립된 모델 사이로 확장됩니다. 모든 질문을 가장 크고 비싼 모델 하나에 보내는 대신, 질문의 성격에 따라 알맞은 모델로 보내는 것입니다. 간단한 질문은 작고 빠른 모델이 처리하고, 어려운 질문만 크고 정확한 모델로 넘기는 식이죠. 이를 모델 라우팅(Routing), 그리고 작은 모델로 먼저 시도하다 자신 없을 때만 큰 모델로 넘기는 방식을 캐스케이딩(Cascading)이라고 부릅니다. 앞서 본 MoE가 '하나의 모델 안에서' Expert를 고르는 것이라면, 이쪽은 '서로 다른 모델들 사이에서' 고른다는 점이 다릅니다. 쿼리 난이도를 판별하거나, 작은 모델의 응답에 대한 확신도를 측정해 라우팅을 결정하는 다양한 방법이 활발히 연구되고 있습니다.
여기까지 오면 하나의 패턴이 보입니다.
- Prefill-Decode 분리: 추론의 '단계'를 쪼갠다
- AFD: 레이어 내부의 '연산'을 쪼갠다
- Speculative Decoding과 모델 라우팅: '모델'을 역할에 따라, 혹은 모델들 사이에서 쪼갠다
분리하는 단위는 다 다르지만, 이들은 ‘하나의 범용 자원으로 모든 것을 처리하는 대신, 작업을 그 성격에 따라 쪼개고 각 조각을 가장 잘 맞는 곳에 배치한다’는 철학에서 시작합니다. 이 원리가 하드웨어에 적용된 것이 이종 컴퓨팅(Heterogeneous Computing)입니다.
추론을 쪼개면 GPU가 못하는 부분들이 드러나고, 그 부분을 채울 칩들이 새로 주목받습니다. 순차적이고 분기가 많은 도구 처리 조각은 CPU가 더 잘 맞아서 인텔·AMD의 CPU 수요가 폭발했고, 저지연 추론 조각을 노린 NVIDIA는 Groq를 샀으며, 에이전트 시대의 오케스트레이션 수요를 본 Arm은 직접 칩을 만들기 시작한 것입니다. AWS와 Cerebras는 Prefill과 Decode를 서로 다른 칩에 나눠 맡기는 솔루션을 내놨고, Google은 TPU 서버를 단계별로 분리해 운영하고 있습니다.
그리고 이 모든 분리를 실제 데이터센터에서 작동시키려면, 수백 개의 칩에 걸쳐 '어떤 요청을 어디로 보낼지'를 실시간으로 결정하는 소프트웨어 계층이 필요합니다. Red Hat, Google Cloud, NVIDIA, AMD, Intel 등이 함께 참여하는 오픈소스 프로젝트 llm-d처럼, 분리된 추론을 오케스트레이션하는 소프트웨어 자체가 하나의 경쟁 영역으로 떠오르고 있습니다.
물론 Disaggregation이 만능은 아닙니다. 단계를 쪼갤수록 KV 캐시 전송, 하드웨어 간 통신, 파이프라인 스케줄링 같은 소프트웨어 계층이 켜켜이 쌓이고, 그중 하나만 어긋나도 전체가 흔들립니다. GPU 생태계는 컴파일러·커널·도구까지 포함한 거대한 플랫폼이라, 아무리 빠른 새 칩도 이 스택을 갖추는 데 수년이 걸립니다. 더 근본적으로는, "Attention은 메모리, FFN은 연산"이라는 전제 위에 세워진 AFD 같은 분리는 Mamba처럼 KV 캐시 부담이 적은 새 아키텍처가 주류가 되면 그 전제 자체가 흔들릴 수 있습니다.
그럼에도 이종 컴퓨팅이 베팅하는 건 'Transformer'라는 특정 아키텍처가 아니라, "상태를 들고 가는 연산인가", "연산이 병목인가 메모리 대역폭이 병목인가" 같이 추상적인 워크로드의 물리적 특성이기 때문입니다. 모델 구조가 바뀌어도 이 특성은 남고, 특성에 따라 쪼개 적합한 하드웨어가 담당한다는 건 앞으로도 쭉 이어질 것입니다.